Coupling spectrum in distributed systems By David Boyne
Coupling spectrum in distributed systems By David Boyne
Struggling with event-driven architecture?
You're not alone. I've seen plenty of teams start with a clean event-driven architecture only to end up with a distributed big ball of mud — broken schemas, unclear ownership, events nobody documented. There's two ways I can help:
We talk about coupling all the time. “We need loose coupling.” “That design is too tightly coupled.” But coupling isn’t a switch you flip. It’s a spectrum, and every point on that spectrum comes with trade-offs you need to understand.
The real question isn’t “are we coupled?” — you’re always coupled to something. The question is where on the spectrum are you choosing to sit, and is that choice intentional?
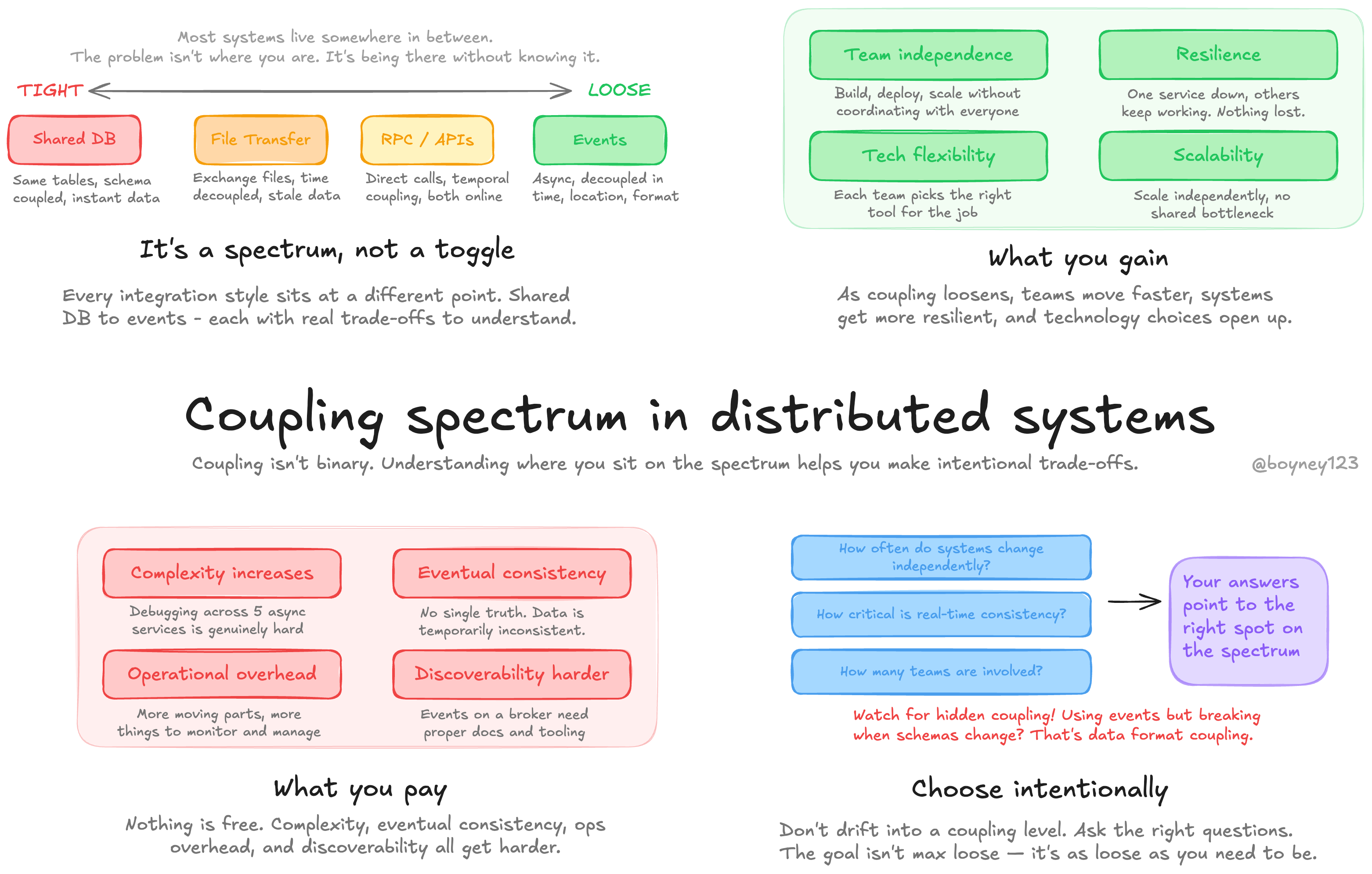
Coupling is a spectrum, not a toggle
-
It’s tempting to think in absolutes. Tightly coupled bad, loosely coupled good. But the reality is far more nuanced than that.
-
At one end you’ve got systems sharing a database, reading each other’s tables directly, completely intertwined. At the other end you’ve got fully autonomous services communicating through asynchronous events, each with their own data store.
-
Most systems live somewhere in between, and that’s fine. The problem isn’t where you are on the spectrum. The problem is being there without knowing it.
Where integration styles sit on the spectrum
Each integration approach gives you a different position on the coupling spectrum. Understanding this helps you pick the right tool for the situation.
-
Shared Database — The tightest coupling. Every application reads and writes the same tables. You get instant consistency and simplicity, but every team is locked together. Schema changes affect everyone. Deployments need coordination. This is where many teams start, and for some use cases it genuinely works. But it doesn’t scale with organisational growth. When shared databases become shared nightmares explores this in depth.
-
Shared Files / File Transfer — A step looser. Systems exchange data through files at agreed intervals. You’re decoupled in time (no need to be online simultaneously), but you’re still coupled to the file format and the timing of those transfers. Data is always stale by some amount.
-
Remote Procedure Calls (RPC / APIs) — Systems call each other directly. You’ve removed the shared data store, which is good. But you’ve introduced temporal coupling — both systems need to be available at the same time. If the downstream service is down, your call fails. You’re also coupled to the API contract. This sits somewhere in the middle of the spectrum.
-
Messaging / Events — The loosest common coupling. Producers publish events without knowing who consumes them. Consumers process at their own pace. You’re decoupled in time, location, and often data format. But you pay for this with eventual consistency and the complexity of reasoning about asynchronous flows.
What you gain as coupling loosens
As you move towards the looser end of the spectrum, you pick up some powerful qualities:
-
Team independence — Teams can build, deploy, and scale their services without coordinating with everyone else. This is often the biggest win in practice.
-
Resilience — If one service goes down, others keep working. Events sit in the broker waiting to be processed. Nothing is lost, nothing blocks.
-
Technology flexibility — Each team can choose the right tool for their job. Different languages, different databases, different deployment strategies. The integration layer doesn’t care.
-
Scalability — Services can scale independently based on their own load patterns rather than being bottlenecked by a shared resource.
What you pay as coupling loosens
Nothing is free. As coupling loosens, new challenges appear:
-
Complexity increases — Distributed systems are harder to reason about. Debugging a request that flows through five services via asynchronous events is genuinely difficult compared to stepping through a single process.
-
Eventual consistency — You give up the comfort of “one database, one truth.” Data across services will be temporarily inconsistent, and your business logic needs to handle that. Eventual consistency is something many teams underestimate until they’re deep in it.
-
Operational overhead — More moving parts means more things to monitor, more infrastructure to manage, and more failure modes to handle. Understanding event delivery failures becomes essential knowledge.
-
Discoverability gets harder — When everything talks directly, you can trace the code. When services communicate through events on a broker, understanding the full picture requires proper documentation and tooling.
Choosing your coupling level intentionally
This is the bit that matters most. Don’t just drift into a coupling level because it was the path of least resistance on day one. Think about it deliberately.
-
Start with the questions — How often do these systems need to change independently? How critical is real-time consistency? How many teams are involved? Your answers point you to the right spot on the spectrum.
-
Different boundaries, different coupling — You don’t need the same coupling level everywhere. Services within a single team might be fine with synchronous calls. Services across organisational boundaries might need full event-driven decoupling. Match the coupling to the relationship.
-
Coupling evolves — Where you start isn’t where you’ll end up. Many successful architectures begin with tighter coupling and loosen it as the system grows and the pain becomes clear. Building event-driven architecture piece by piece covers this incremental approach.
-
Watch for hidden coupling — This is the sneaky one. You might think you’re loosely coupled because you use events, but if every consumer breaks when you add a field to your event schema, you’ve got data format coupling. If consumers depend on events arriving in a specific order, you’ve got temporal coupling hiding behind the broker.
-
Like always, it depends on your use case. The goal isn’t to be as loosely coupled as possible. It’s to be as loosely coupled as you need to be, and no more.
Extra Resources
-
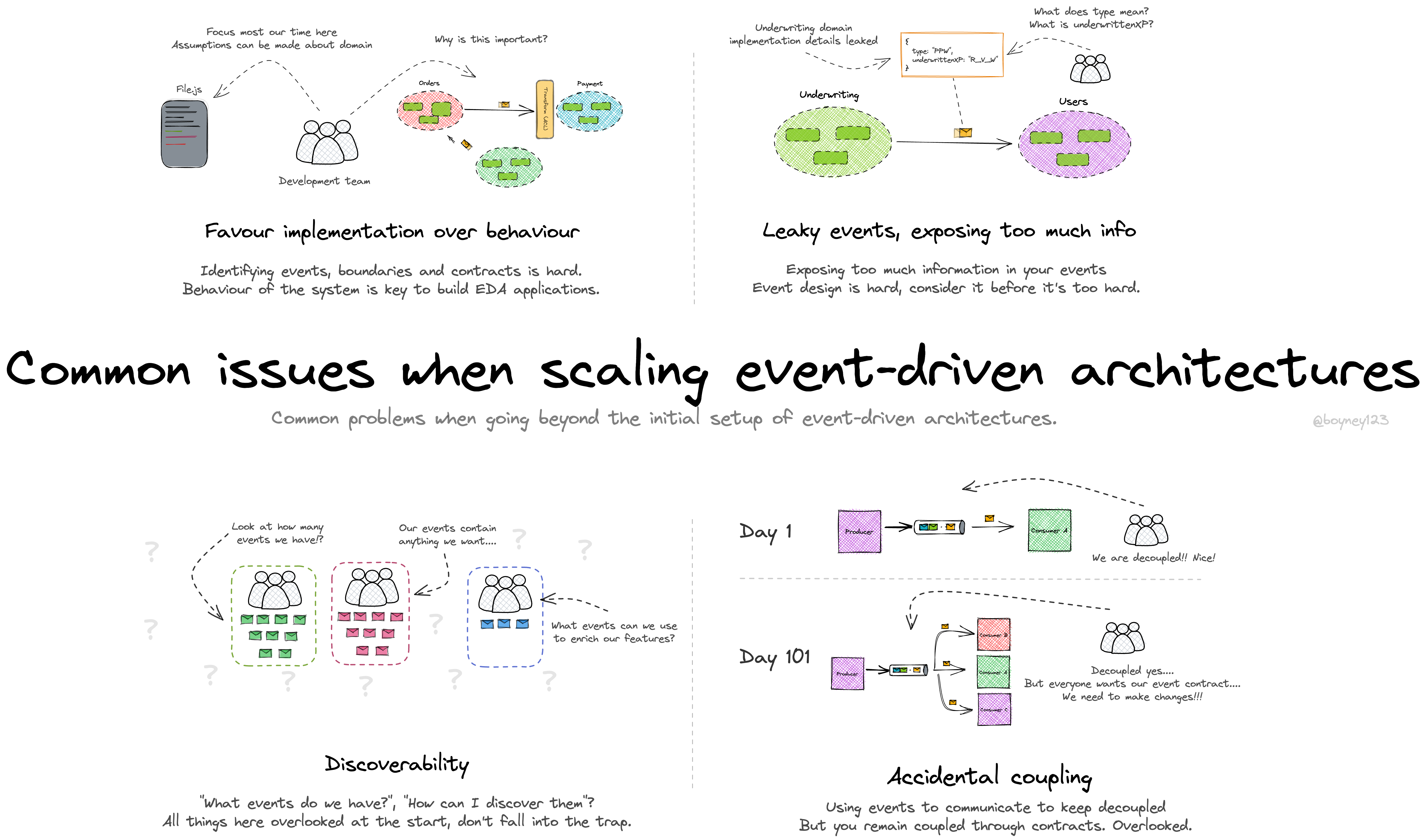
Good and hard parts of event architectures - A balanced look at what event-driven architecture gives you and what it asks of you. Useful context for understanding the loose end of the coupling spectrum.
-
Sync vs Async - Understanding the difference between synchronous and asynchronous communication is foundational to understanding coupling trade-offs.
-
When shared databases become shared nightmares - A deep dive into the tightest end of the coupling spectrum and why teams often need to move away from it.
-
Eventual consistency - The trade-off you accept when you move towards looser coupling. Worth understanding deeply before you commit.
-
Enterprise Integration Patterns - The book by Gregor Hohpe and Bobby Woolf. Chapter 2 covers the four integration styles and their coupling characteristics in depth.
-
Building event-driven architecture piece by piece - You don’t have to jump to the loosest coupling overnight. An incremental approach often works best.
Explore other visuals
Want to work together?
If you're interested in collaborating, I offer consulting, training, and workshops. I can support you throughout your event-driven architecture journey, from design to implementation. Feel free to reach out to discuss how we can work together, or explore my services on EventCatalog.
EDA Visuals: The book
Join over 13,000 others learning EDA and download all the EDA visuals directly to your computer.
This book contains all the visuals in one book, you can download, read offline and explore.
If you would like to support my work, you can purchase the book. This helps keeping the visuals free for the community. Purchase the book
