When shared databases become shared nightmares By David Boyne
When shared databases become shared nightmares By David Boyne
Struggling with event-driven architecture?
You're not alone. I've seen plenty of teams start with a clean event-driven architecture only to end up with a distributed big ball of mud — broken schemas, unclear ownership, events nobody documented. There's two ways I can help:
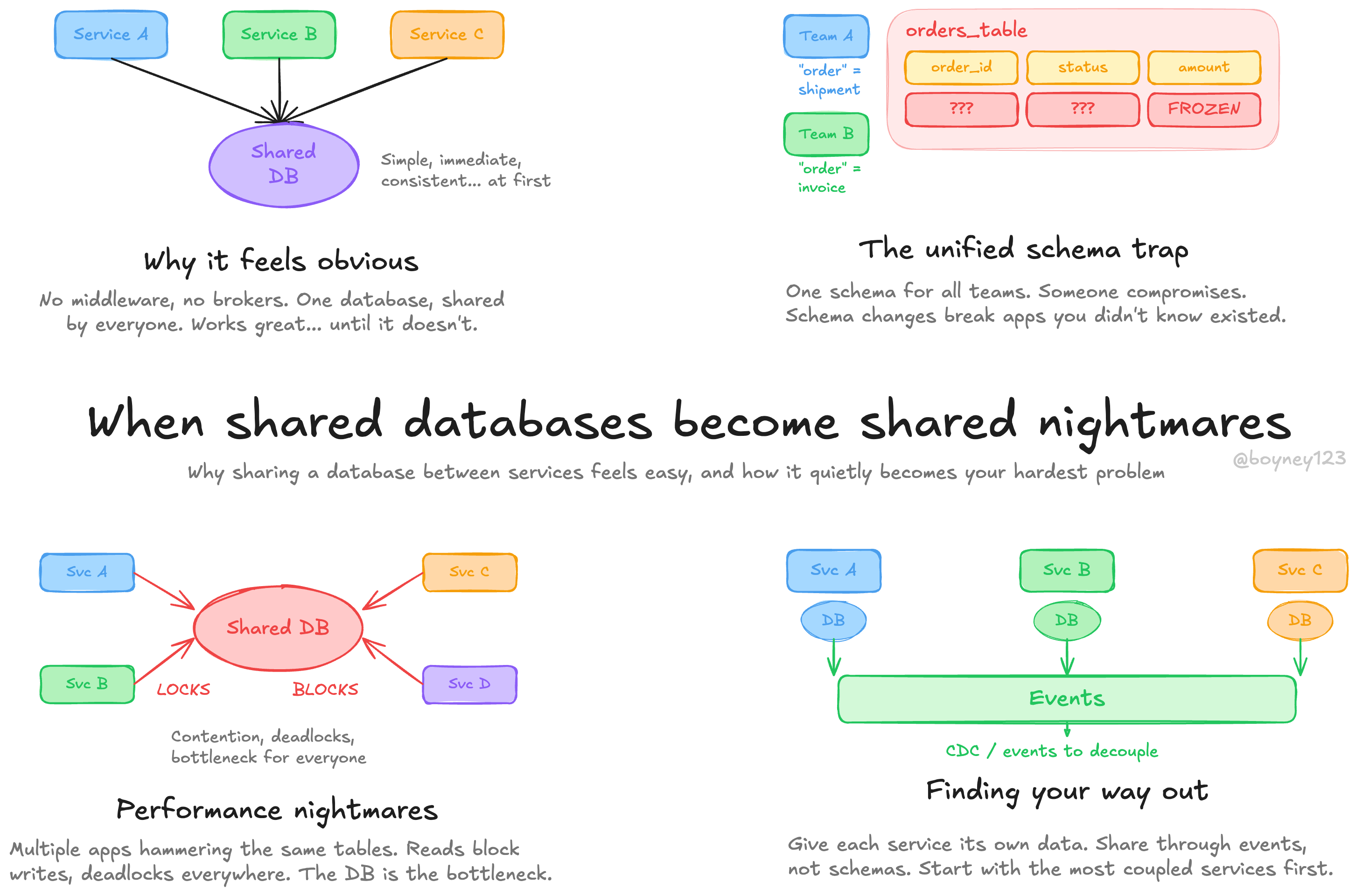
If you’ve ever integrated two applications by pointing them at the same database, you’re not alone. It’s the path of least resistance. No middleware, no message brokers, no new technology to learn. One database, shared by everyone, always consistent. Sounds great, right?
It works brilliantly… until it doesn’t. And by the time it doesn’t, you’re in deep.
Why it feels like the obvious choice
-
It’s immediate. Any application can read the latest data the moment it’s written. No lag, no eventual consistency to reason about.
-
Everyone already knows SQL. You don’t need to introduce new infrastructure or learn a messaging platform. The technology is already there.
-
Consistency feels free. Transactions handle concurrent writes, and you get a single source of truth without building anything extra.
-
These are real benefits, and for small systems with a couple of tightly-related applications, a shared database can genuinely be fine. The trouble starts when you scale beyond that.
The unified schema trap
-
To share a database, every application needs to agree on the schema. That means one model has to represent how all your applications see the world. This is technically hard and politically harder.
-
Different teams model the same concepts differently. An “order” in the warehouse system is not the same thing as an “order” in billing. Forcing them into one schema means someone compromises, and that compromise ripples through their codebase.
-
Changing the schema becomes terrifying. A column rename, a table restructure, a new constraint — any of these can break applications you didn’t even know were reading that table. The schema becomes frozen, and frozen schemas mean frozen innovation.
-
The political side is real too. Which team owns the schema? Who decides when it changes? These conversations can stall entire projects.
Performance and locking nightmares
-
Multiple applications hammering the same tables leads to contention. Reads block writes, writes block reads, and suddenly your database is the bottleneck for every service in your organisation.
-
Deadlocks become a regular occurrence when different applications lock rows in different orders. Debugging these across application boundaries is painful.
-
If your applications are distributed across multiple machines or regions, now your database needs to be distributed too. Distributed databases with locking conflicts can bring your entire system to a crawl.
It blocks teams from moving independently
-
When every application shares a database, every team is coupled to every other team. You can’t deploy independently because your schema change might break someone else’s service.
-
This is the hidden cost that hurts the most over time. Teams slow down. Releases get coordinated. What started as a simple integration becomes the thing that prevents your organisation from iterating.
-
The more applications that share the database, the worse this gets. It’s a form of coupling that grows silently and compounds over time.
Finding your way out
-
The path forward is giving each service ownership of its own data. This aligns well with bounded contexts — each domain owns its data store and exposes what it chooses to share.
-
Change data capture (CDC) can help you transition. It lets you capture changes from a shared database and publish them as events, giving you a migration path without a big-bang rewrite.
-
Events let applications share data without sharing a schema. Each consumer can transform the event into its own internal model, keeping domain boundaries clean.
-
This is a journey, not a switch you flip overnight. Start by identifying which applications are most tightly coupled through the shared database, and decouple those first. Building event-driven architecture piece by piece is a valid approach here.
-
Remember, the goal isn’t to eliminate databases — it’s to stop using them as your integration layer. Databases are brilliant at what they do. Integration between autonomous services isn’t one of those things.
Extra Resources
-
Bounded context with event architectures - Understanding boundaries is the first step to breaking out of shared database coupling.
-
Understanding change data capture - CDC can be your migration path from a shared database to events. Worth exploring if you’re stuck in this situation.
-
Reducing team cognitive load with EDA - A visual on how event-driven architecture helps teams work more independently.
-
Enterprise Integration Patterns - The book by Gregor Hohpe and Bobby Woolf that explores integration styles in depth. Chapter 2 covers the shared database pattern and its trade-offs.
-
Data on the Outside vs Data on the Inside - Pat Helland’s influential paper on why data inside a service boundary is fundamentally different from data shared between services.
-
Building event-driven architecture piece by piece - You don’t have to rip everything apart at once. This visual covers an incremental approach.
Explore other visuals
Want to work together?
If you're interested in collaborating, I offer consulting, training, and workshops. I can support you throughout your event-driven architecture journey, from design to implementation. Feel free to reach out to discuss how we can work together, or explore my services on EventCatalog.
EDA Visuals: The book
Join over 13,000 others learning EDA and download all the EDA visuals directly to your computer.
This book contains all the visuals in one book, you can download, read offline and explore.
If you would like to support my work, you can purchase the book. This helps keeping the visuals free for the community. Purchase the book
